artificial intelligence
CEPEJ (European Commission for the Efficiency of Justice) is one of the main sources for those who like comparative law. In its last plenary session (12/08/2021), a Four-Year Action Plan was approved, with the objective of adopting new technologies for the improvement of Justice.
The plan intends to reconcile, with the help of technology, the effectiveness of the provision with the quality of jurisdictional public services. The axes that support this strategy are transparency, collaboration, valuing people, accessibility, rationality, responsibility and responsiveness.
At the same time, on the same occasion, CEPEJ revised its planning for the promotion of the ethical use of artificial intelligence (AI) by the Judiciary. The currently revised work began in 2018, when five key points for adopting AI solutions were established : respect for fundamental rights; non-discrimination; data quality and security; transparency, impartiality and fairness; as well as the independence of the user.
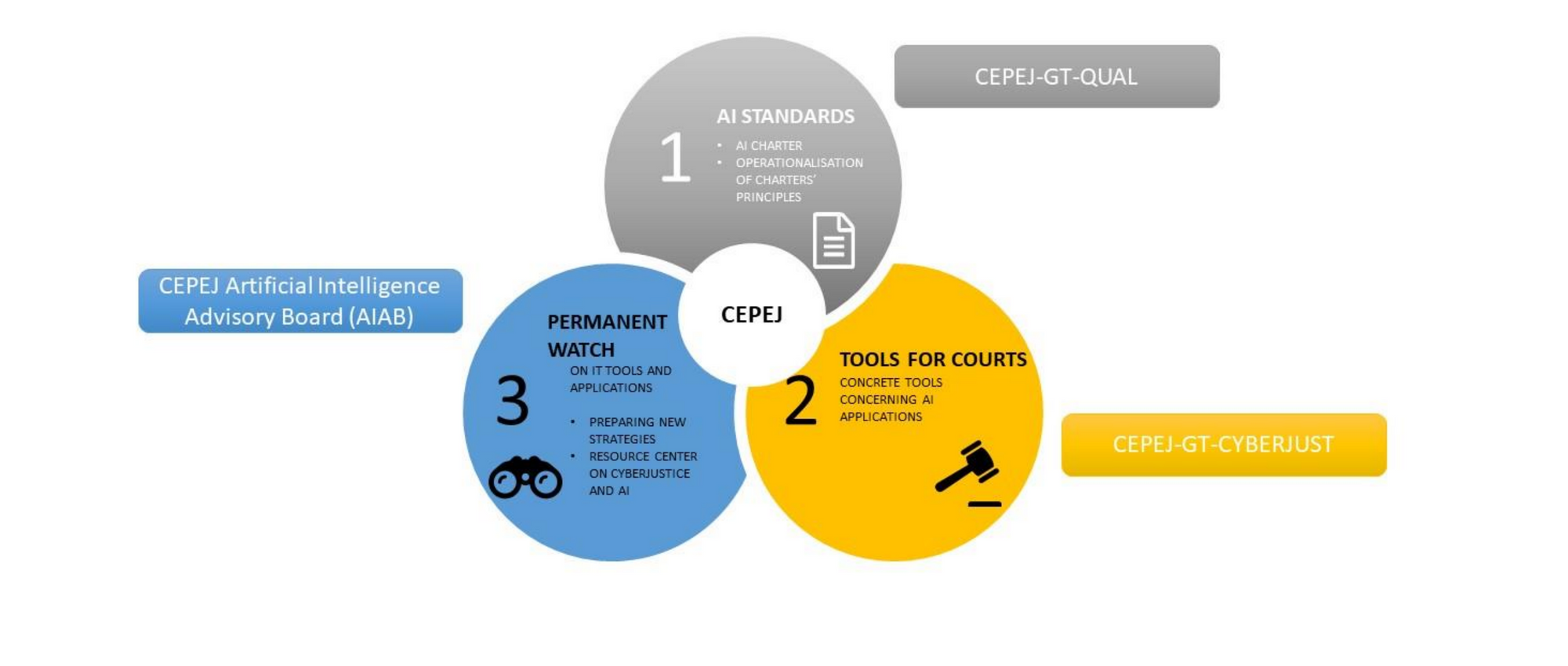
From the beginning, CEPEJ has shown that it is aware that there is no magic solution to the matter, especially considering its pioneering spirit in trying to establish conditions for AI to advance while respecting human rights. Two years later, the same initial working group aimed to assess the feasibility of this mission, having presented its report in 2020.
In mid-2021, the first version of the planning for certification of AI solutions was presented. But, taking into account the discussions that had taken place and the difficulty in creating a solution that respected the vision of several countries, the conclusion of the work was postponed to the end-of-year plenary meeting.
The objective of this initiative (moved by the Council of Europe), despite its initial stage, is to regulate high-risk AI solutions. As there are many countries involved, it is natural that Europe does not move so quickly on this point. As an example, Brazil already has a regulation of the matter, including guidelines set by the CNJ. On this point we can say that we are more advanced than Europe.
AI in Folha de São Paulo: article or publi?
Commentary on the articles of Folha de São Paulo on applications of artificial intelligence in the world of Law.
Folha de São Paulo recently published a series of articles on artificial intelligence. Despite the unusual announcement, the article was not promoted as an advertorial. This is the headline of the article from 02/20/20:
And this is its footer:
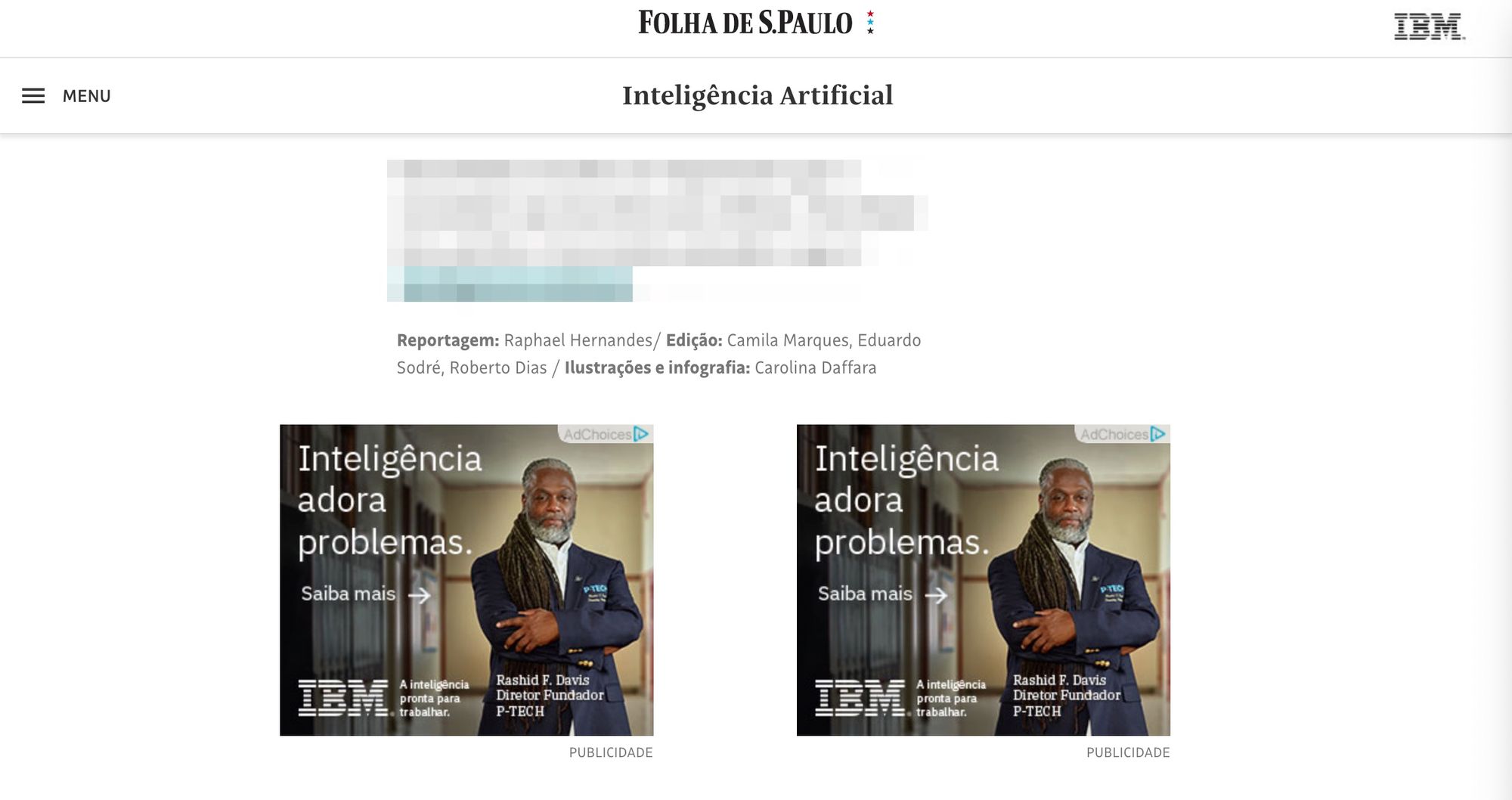
That is, it may not even be an advertorial, but it is a sponsored column for sure. This demonstrates that Folha is engaged in an educational activity (commendable), which does not exempt us from considering sponsors when we find some news that is especially interesting to us.
Very well. In this context, Folha also published on 03/10/20: "Artificial intelligence acts as a judge, changes lawyer strategy and promotes intern".

As I don't know if my comment would be authorized in Folha's system, I left here my reading script for the article. I hope that, with these warnings, the article will become more informative about the use of Artificial Intelligence (AI) in Law:
- Folha: "According to the most recent version of "Justice in Numbers" (...), 108.3 million cases began in a digital version from 2008 to 2018." Me: This is not very relevant to AI, since what was transferred to the digital platform was the processing. The records are still normal PDFs, which do not easily provide the kind of data that intelligent systems consume.
- Folha: "Illustration of Diana, the name given to the artificial intelligence program of the law firm Lee, Brock e Camargo Advogados". Me: Really?
Folha: "Macêdo uses the system on a daily basis, named Elis (in the Pernambuco Judiciary)". Me: It's okay that naming things is fun. But do we need another robot in 2020?
Folha: "In the text of the decision itself, it is saying that it was Elis who did it, to allow transparency in the process, so that it is known what is being used." Me: Do you put in the decision what was done in Word or typewriter?
Folha: "According to Juliana Neiva, the court's secretary of Information and Communication Technology, the development of AI had zero cost for the court, as it was developed by the body's own servers." Me: Are the servers zero cost?
Folha: "The STJ wants to go further in the use of technology and reports that the Socrates 2 project is already underway, in which the idea is to move forward so that AI will soon provide judges with all the elements necessary for the judgment of the causes, such as the description of the parties' theses and the main decisions already made by the court in relation to the subject of the case." Me: Is AI the best (or only) way to do this?
Folha: "To deal with this problem, the law firm Lee, Brock e Camargo Advogados (LBCA) developed an application linked to an AI system. The mechanism makes it possible to raise, soon after knowing who the opposing party's deponents are, everything that these witnesses have already said in other processes, says Solano de Camargo, founding partner of LBCA. Me: Does anyone think they need AI for that? Is this really a central problem for a mass litigation firm? Isn't the important thing to know what the witness will say about the facts of that particular case?
Folha: "The firm's AI system was named Diana and has already consumed investments of R$ 3 million in recent years, says Camargo. The cost includes the implementation of an internal technology laboratory that has 41 members." Me: With 41 members, you don't even need artificial intelligence. The whole point of technology is to give more productivity so that you can have small teams.
Folha: "Examples of use: The law firm Lee, Brock e Camargo Advogados (LBCA), in São Paulo, developed an AI system and an application connected to it. The firm's lawyers can open the app during hearings and use the software's analysis to identify, for example, contradictions of a witness while he or she is speaking to the judge." Me: I need to write a post about this.
Folha de São Paulo is a very important newspaper and, in my view, it should be more selective in its publications. It is natural for a newspaper to have advertisers. It is not normal, however, to misinform in this way. It would be very cool for Folha to follow up on the article in a less captured way. Or else it would make it clearer who the advertiser is, otherwise it would become just another page on the internet.
At last British Legal Technology Forum , held in London this week, several issues related to artificial intelligence applied to law were discussed. The blog Artificial Lawyer was there and published an interesting reflection on a new wave of opinions about artificial intelligence, which he called "Post-Hype AI Hype".
For those who are not familiar, Hype is something exaggerated and with a negative connotation . Any subject that is giving something to talk about, that is fashionable, but that at the same time has no proven foundation, is hyped. In the context of technology, something that is in hype brings with it a great fear that the current state of technology is not enough to solve the problems it proposes to face.
The current movement, diagnosed this week, maintains that the cycle of exacerbated expectations about The potential of artificial intelligence is coming to an end . Instead of discussing a distant future, this movement aims to reflect on practical and immediate applications, which generally require technologies that are already established. In other words, a new cycle has formed in the sector against artificial intelligence - but it is also a kind of hype.
Basically, We now have a new hype taking the place of the other . None of them were deliberately created, because they were composed of a sum of voices that really believed in what they promised as a solution to all problems. Today, retreaded, the hype is organized to avoid the terminology celebrated until then, but this is not something that comes without any difficulty. After all, albeit imprecisely, artificial intelligence is already a term incorporated into the current vocabulary. In any case, this has made communication possible so far.
Debating related issues talking about machine learning, natural language processing, automatic decision classification, among other terms, is something that would require much more energy. This is certainly not in the interest of companies that use jargon only as marketing, with no commitment to embedding the technology they advertise in their products.
It seems that the term artificial intelligence has lost its freshness . At the same time - and not by chance - some of its promises were simply not fulfilled for the legal market. We are experiencing a hangover similar to the one that medicine recently passed, as artificial intelligence has not discovered the "cure for cancer". And we still don't have the "cure for the processes".
From cycle to cycle, hype reveals itself as the very way of being of professional communities with limited control over what should be discussed and understood in depth. Once installed, it does not dissolve easily, being succeeded by a new promise that will not be fulfilled either. This chain of promises and frustrations is typical of sectors that consume technology, without having the tools to fully understand it.
Like this The hype is a consequence of our own lack of technical mastery , of our consequent superficiality in this field. Additional ingredients are the interest of people to feed the hype, for example, a lecturer who reaffirms their supposed knowledge or companies that sell the hype, as they work in the logic of immediate and facilitated communication.
The final elements are the words intelligence and artificial, which convey a very equivocal sense of what they really are when used together. It would be better if this technology did not have its content induced by words that we think we understand, because they are part of our language in other contexts.
Although a lawyer fully understands the legal challenges of his daily work, he would hardly understand everything that technologically surrounds the products available in his market. If he were told that the solution to his problems would be to use artificial intelligence, he would most likely be misled. After all, he may mistakenly imagine what it is about. In contrast, the same lawyer would not be affected if he received advice to use a "graph bank" solution.
Technical names do not communicate and do not sell either. In this sense, artificial intelligence is a victim of this unfortunate coincidence. To escape the new hype, it will be necessary for our community to dedicate itself to understanding what artificial intelligence really is and what its real possibilities are. Otherwise, we will continue in the succession of hypes , which alienate more than they inform.
This post is part of a series. Before reading, see the Previous post .
Convinced of the usefulness of a classifier of judicial decisions as to their outcome, we began to organize the data. The first step was to download the STF's rulings and develop a relational model to structure the information. Basically, it was necessary to build a collection and the fields in which each judgment would be fragmented.
For this purpose, a computer program was developed capable of downloading and storing the data separated by judgment, class, number and, especially, with the identification of the respective judgment certificate. As it seems intuitive, This is a phase that requires a huge investment in terms of technology, combined with the attention of the team of jurists to separate the parts of the judgment to be consulted for the subsequent classification of the decisions.
We have separated the essentials in a very detailed way and kept some information in a raw state for later review. We divided the team into those responsible for reading the judgment certificates of each procedural class, starting with the following: writ of mandamus, complaint, habeas corpus and extraordinary appeal. We decided not to work with other processes, as they were very small in number.
While the first classes had a few thousand judgments each, the extraordinary appeals were evaluated in a much larger volume. In fact, its greater volume has always been an obstacle to empirical research on diffuse control of constitutionality, as more organization is needed to work on decisions in the tens of thousands of lines. It's really not something that a researcher can just do .
We organized this data on an annotation platform, in such a way that, together, the team of jurists would be able to propose an initial model for classifying the results of the judgments. After much discussion about the options of building a more complex or simpler classifier, the following model emerged:
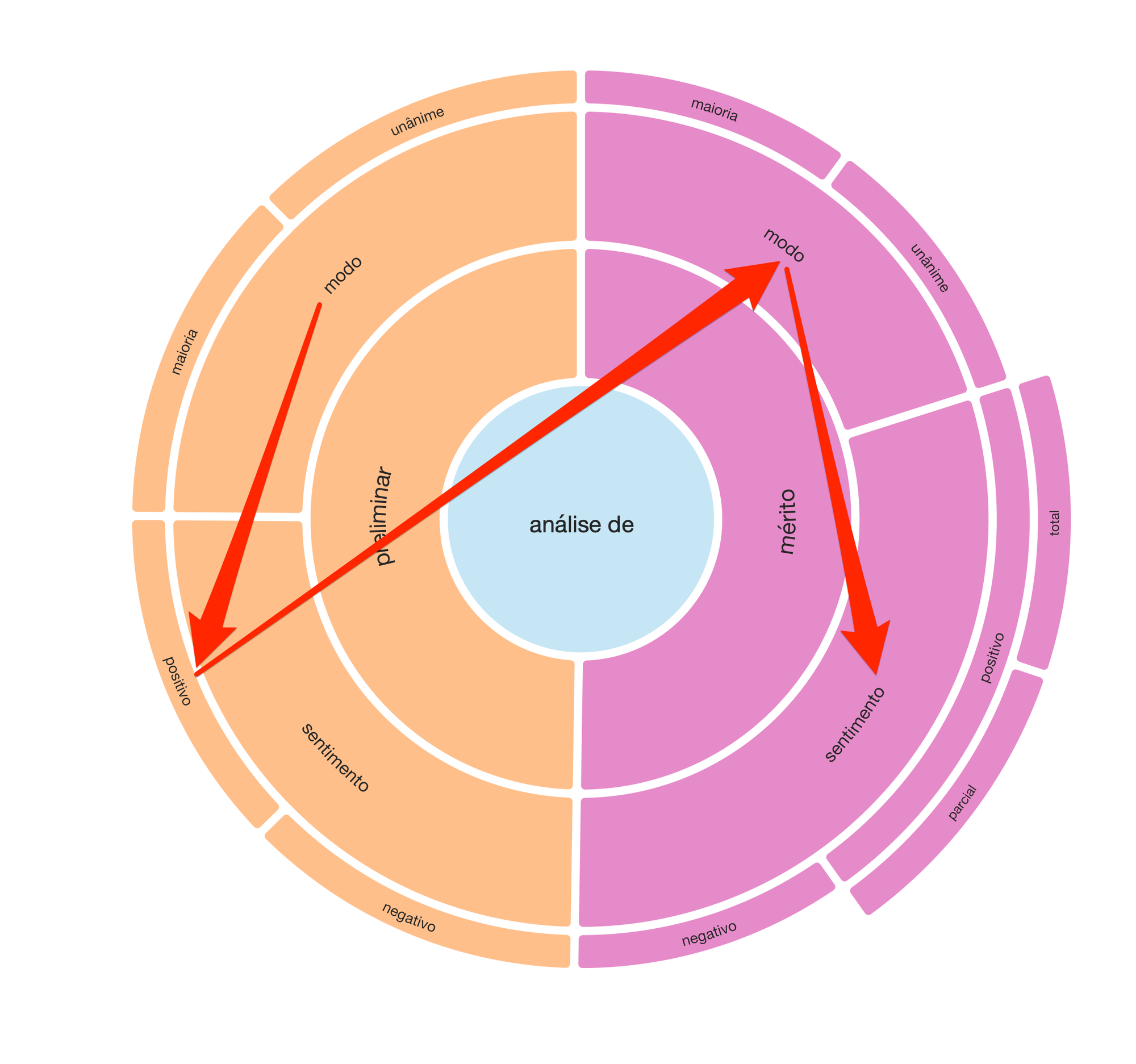
We therefore decided to make a preliminary judgment (by majority or unanimity), which, if positive, would lead to the evaluation of the merits. Likewise, the judgment on the merits was bipartite in its modes (majority or unanimity) and respective outcomes: positive and negative. Finally, specifically for the judgment of positive merit, we also divide the evaluation by the scope of the provision: total or partial.
From this sequence of judgments, illustrated in the radial, we would be able to expand the sample to the tens of thousands of judgments in a consistent way.
What was missing was only a note-taking platform that would be able to house this work, allowing researchers simultaneous access to the collection. We then transfer the collection to a cloud infrastructure equipped with this capacity and start the classification. A simplified example of how data is structured, taking writs of mandamus as an example, is the following:
Although some parts of the table have been omitted (which preserves the originality of the research until its publication), it is already possible to notice the structure we set up for annotation of the mode (majority or unanimous). As an example, in the case of extraordinary appeals, we classified 3,972 judgments as unanimous, with the following variations: unanimous, unanimous, unanimous, agreement of votes and uniform decision.
This means that, at this point, Our database now has almost four thousand links properly labeled. They are real processes, of which we know several attributes. The same philosophy applies to the vocabulary present in the collection to classify the outcome (positive or negative) of the judgment. The difference is that there are not just five, but hundreds of variations of words used to translate the outcome of a judgment.
As we know a lot about each of these processes, it becomes possible to train a machine so that, recognizing a pattern, it suggests a label contemplating the mode (e.g., unanimous) and the outcome (e.g., unfavorable) in the face of a new judgment that may be handed down. Thus, we teach the machine to quickly classify thousands of new decisions, based on the curation carried out by our researchers.
Machine learning itself is also not a trivial task and will be the subject of a new post. So far, we have only dealt with data preparation , which is an essential and often overlooked step. Without properly organized data, it is not possible to develop artificial intelligence solutions.
This post is part of a series. Before reading, see the Previous post .
Convinced of the usefulness of a classifier of judicial decisions as to their outcome, we began to organize the data. The first step was to download the STF's rulings and develop a relational model to structure the information. Basically, it was necessary to build a collection and the fields in which each judgment would be fragmented.
For this purpose, a computer program was developed capable of downloading and storing the data separated by judgment, class, number and, especially, with the identification of the respective judgment certificate. As it seems intuitive, This is a phase that requires a huge investment in terms of technology, combined with the attention of the team of jurists to separate the parts of the judgment to be consulted for the subsequent classification of the decisions.
We have separated the essentials in a very detailed way and kept some information in a raw state for later review. We divided the team into those responsible for reading the judgment certificates of each procedural class, starting with the following: writ of mandamus, complaint, habeas corpus and extraordinary appeal. We decided not to work with other processes, as they were very small in number.
While the first classes had a few thousand judgments each, the extraordinary appeals were evaluated in a much larger volume. In fact, its greater volume has always been an obstacle to empirical research on diffuse control of constitutionality, as more organization is needed to work on decisions in the tens of thousands of lines. It's really not something that a researcher can just do .
We organized this data on an annotation platform, in such a way that, together, the team of jurists would be able to propose an initial model for classifying the results of the judgments. After much discussion about the options of building a more complex or simpler classifier, the following model emerged:
We therefore decided to make a preliminary judgment (by majority or unanimity), which, if positive, would lead to the evaluation of the merits. Likewise, the judgment on the merits was bipartite in its modes (majority or unanimity) and respective outcomes: positive and negative. Finally, specifically for the judgment of positive merit, we also divide the evaluation by the scope of the provision: total or partial.
From this sequence of judgments, illustrated in the radial, we would be able to expand the sample to the tens of thousands of judgments in a consistent way.
What was missing was only a note-taking platform that would be able to house this work, allowing researchers simultaneous access to the collection. We then transfer the collection to a cloud infrastructure equipped with this capacity and start the classification. A simplified example of how data is structured, taking writs of mandamus as an example, is the following:
Although some parts of the table have been omitted (which preserves the originality of the research until its publication), it is already possible to notice the structure we set up for annotation of the mode (majority or unanimous). As an example, in the case of extraordinary appeals, we classified 3,972 judgments as unanimous, with the following variations: unanimous, unanimous, unanimous, agreement of votes and uniform decision.
This means that, at this point, Our database now has almost four thousand links properly labeled. They are real processes, of which we know several attributes. The same philosophy applies to the vocabulary present in the collection to classify the outcome (positive or negative) of the judgment. The difference is that there are not just five, but hundreds of variations of words used to translate the outcome of a judgment.
As we know a lot about each of these processes, it becomes possible to train a machine so that, recognizing a pattern, it suggests a label contemplating the mode (e.g., unanimous) and the outcome (e.g., unfavorable) in the face of a new judgment that may be handed down. Thus, we teach the machine to quickly classify thousands of new decisions, based on the curation carried out by our researchers.
Machine learning itself is also not a trivial task and will be the subject of a new post. So far, we have only dealt with data preparation , which is an essential and often overlooked step. Without properly organized data, it is not possible to develop artificial intelligence solutions.
Legal professionals consume several types of legal information, two of which are the main ones: law and jurisprudence. The law is an abstract norm, that is, it has not been applied to a concrete case. Jurisprudence, on the other hand, is a concrete rule, made to solve a case submitted to the Judiciary.
Although it is relatively easy to know the laws, as they are published in official repositories, it is much more complex to know the jurisprudence. The most widely used legislative repository is that of the Plateau and it illustrates well how the various forms of federal legislation are organized and consumed in Brazil. In contrast, There are several courts and each one is responsible for publishing its own jurisprudence .
In general, courts treat such data as natural language documents, with a relatively limited additional layer of metadata.
Thus, there are few filters to access this information, for example: the date of the judgment, the name of the judge, the body to which this judge belongs, the name and position of each party in the process, etc. We did not, however, find any public repository organized around the dimension of the result of the judgment, whether favorable or unfavorable its outcome.
Let's consider the following use case:
It is possible to imagine that a lawyer from a bank does a research on case law in a certain court to assess the chance of success of a new lawsuit.
As the STF's judgment base is indexed, it can, with some ease, find concrete cases that dealt with a certain topic. However, the lawyer has a lot of difficulty in finding, within this topic, which were the cases won by banks and in which the same banks were defeated.
The usefulness of developing a solution that understands which are the favorable and unfavorable cases lies in enabling an aggregate consultation also by this dimension, referring to the result of the judgment. After all, the professional consultation almost always has an interested side, in such a way that knowing the outcome of the case is very important information for the practical life of legal professionals.
In the coming weeks, we will publish here the journey of several of DireitoTec's researchers, dedicated to mapping tens of thousands of STF judgments. This will make it possible to create a foundation for artificial intelligence training in such a way that it is possible to automatically classify the outcome of a judgment. What about? Sounds promising?
This post is part of a series. See the Next post .
Legal professionals consume several types of legal information, two of which are the main ones: law and jurisprudence. The law is an abstract norm, that is, it has not been applied to a concrete case. Jurisprudence, on the other hand, is a concrete rule, made to solve a case submitted to the Judiciary.
Although it is relatively easy to know the laws, as they are published in official repositories, it is much more complex to know the jurisprudence. The most widely used legislative repository is that of the Plateau and it illustrates well how the various forms of federal legislation are organized and consumed in Brazil. In contrast, There are several courts and each one is responsible for publishing its own jurisprudence .
In general, courts treat such data as natural language documents, with a relatively limited additional layer of metadata.
Thus, there are few filters to access this information, for example: the date of the judgment, the name of the judge, the body to which this judge belongs, the name and position of each party in the process, etc. We did not, however, find any public repository organized around the dimension of the result of the judgment, whether favorable or unfavorable its outcome.
Let's consider the following use case:
It is possible to imagine that a lawyer from a bank does a research on case law in a certain court to assess the chance of success of a new lawsuit.
As the STF's judgment base is indexed, it can, with some ease, find concrete cases that dealt with a certain topic. However, the lawyer has a lot of difficulty in finding, within this topic, which were the cases won by banks and in which the same banks were defeated.
The usefulness of developing a solution that understands which are the favorable and unfavorable cases lies in enabling an aggregate consultation also by this dimension, referring to the result of the judgment. After all, the professional consultation almost always has an interested side, in such a way that knowing the outcome of the case is very important information for the practical life of legal professionals.
In the coming weeks, we will publish here the journey of several of DireitoTec's researchers, dedicated to mapping tens of thousands of STF judgments. This will make it possible to create a foundation for artificial intelligence training in such a way that it is possible to automatically classify the outcome of a judgment. What about? Sounds promising?
This post is part of a series. See the Next post .
US President Donald Trump recently signed (11/02/19) a " executive order " to, in these words, "maintain the leadership" of the country in the field of artificial intelligence. Although it is undeniable that the US plays a very important role in this area, it is not so simple to position oneself as a leader. In fact, the very concern with maintaining a supposed lead demonstrates that there is at least one serious threat in this race for AI, in which China has been standing out a lot.
More than a promise: years of budget
To carry out this mission, a Committee linked to the National Science and Technology Council (NSTC) was appointed, in such a way that broad coordination of the American federal government, including all its agencies, is expected. Directors of these agencies are encouraged, from now on, to prioritize investments in AI, making their budget proposals contemplate investments in the area and, especially, during the coming years.
In other words, there is a concern to provide funds for the initiative and the program recognizes that the development of AI is something that, in addition to money, also consumes a lot of time. And this coexists with a sense of urgency, as the act sets a deadline of 90 days for each agency to indicate how it intends to commit its annual budget to achieve the objectives set by the rule.
Strategic principles and objectives
Trump's act is guided by five principles: promotion of science, economic competitiveness and national security; lowering barriers to AI experiments in order to broaden its use; educating citizens to face the economic revolution caused by technology; guarantee of civil liberties and privacy; as well as maintaining the strategic position of the US in the world AI market.
It seems like a good summary of everything this technology promises in terms of advances and also risks arising from it. Thus, at the same time that Trump reinforces the strategic importance of being a protagonist in the export of AI, he delimits that this asset must be protected so that it does not fall into the hands of commercial adversaries and, especially, enemies. Trump is also committed to maintaining the employability of American citizens, in view of the announced extinction [in my view, prematurely] of several professions.
The principles listed should be aimed at, within the scope of the federal government, achieving six strategic objectives: converting AI research into innovation applied to practice; increase the supply of data and expand access to specialized computers; preserve security and privacy, even in the face of the expansion of AI uses; reduce the vulnerability of systems to malicious attacks; ensure that public and private employees are able to use new technologies; and, finally, to maintain US leadership in the area.
The timeline and deadlines
In addition to establishing competencies, principles and strategic objectives, the "executive order" creates a schedule for them to be achieved. The first step is the improvement in the provision of data by the federal government, which is recognized as a bottleneck for the development of AI.
A public call is planned to, within 90 days, identify the demands of civil society and academia in relation to which services should be prioritized. Within 120 days of the publication of the act, with the support of the Ministry of Planning (OMB), the Federal Committee for Artificial Intelligence (Select Committee) must update the guidelines for the implementation of data and software repositories, with the aim of improving the retrieval and use of information.
In addition to these predictions, the "executive order" creates a series of urgent milestones for the cycle to be successful, starting with the demands of data scientists and closing with meeting them. In other words, it is a planning guided by the use and purpose that society wants to give to data. The American government is not saying what should be done, calling itself only the duty to organize the data, so that there are no leaks or violations of privacy.
My Take: Race Against China
In my view, Trump's new act is very correct and reveals the real clash of two powers. China is the leader in information gathering (including questionably) and is rapidly advancing with its processing capacity. The U.S., on the other hand, may even be seen as a leader in AI research, but it depends on more data to keep fighting. Therefore, the act reorganizes the foundations of the American public data structure. After all, without data, it's impossible to make progress in data science.
Apparently, when it comes to AI, judging by the deadlines and milestones outlined in the American standard, time is also money. In fact, a lot of money. Proof of this is that the US is redoing the foundations, and not a mere renovation of the roof.