Classifying Judicial Decisions with Artificial Intelligence: Part Two
This post is part of a series. Before reading, see the Previous post .
Convinced of the usefulness of a classifier of judicial decisions as to their outcome, we began to organize the data. The first step was to download the STF's rulings and develop a relational model to structure the information. Basically, it was necessary to build a collection and the fields in which each judgment would be fragmented.
For this purpose, a computer program was developed capable of downloading and storing the data separated by judgment, class, number and, especially, with the identification of the respective judgment certificate. As it seems intuitive, This is a phase that requires a huge investment in terms of technology, combined with the attention of the team of jurists to separate the parts of the judgment to be consulted for the subsequent classification of the decisions.
We have separated the essentials in a very detailed way and kept some information in a raw state for later review. We divided the team into those responsible for reading the judgment certificates of each procedural class, starting with the following: writ of mandamus, complaint, habeas corpus and extraordinary appeal. We decided not to work with other processes, as they were very small in number.
While the first classes had a few thousand judgments each, the extraordinary appeals were evaluated in a much larger volume. In fact, its greater volume has always been an obstacle to empirical research on diffuse control of constitutionality, as more organization is needed to work on decisions in the tens of thousands of lines. It's really not something that a researcher can just do .
We organized this data on an annotation platform, in such a way that, together, the team of jurists would be able to propose an initial model for classifying the results of the judgments. After much discussion about the options of building a more complex or simpler classifier, the following model emerged:
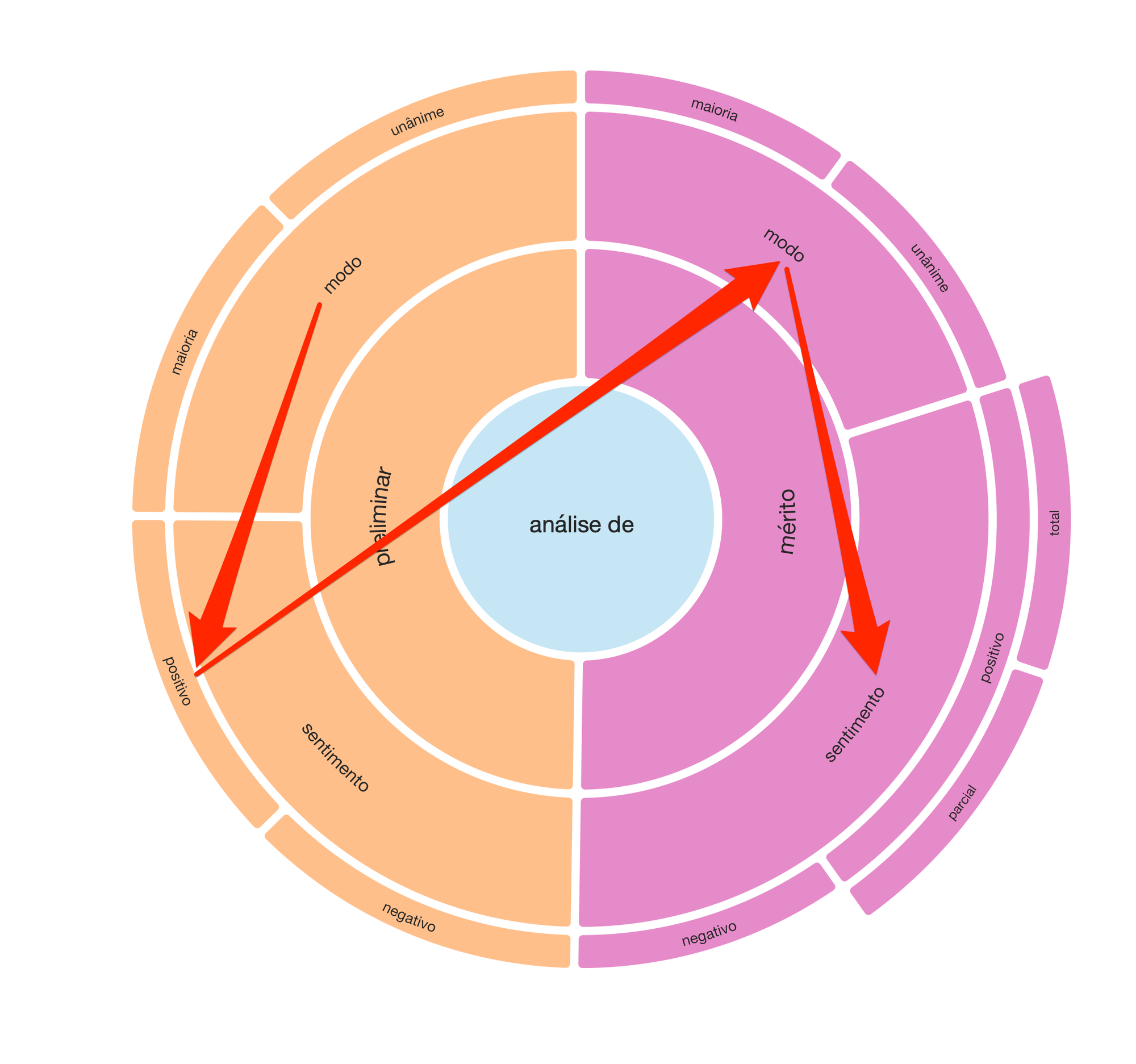
We therefore decided to make a preliminary judgment (by majority or unanimity), which, if positive, would lead to the evaluation of the merits. Likewise, the judgment on the merits was bipartite in its modes (majority or unanimity) and respective outcomes: positive and negative. Finally, specifically for the judgment of positive merit, we also divide the evaluation by the scope of the provision: total or partial.
From this sequence of judgments, illustrated in the radial, we would be able to expand the sample to the tens of thousands of judgments in a consistent way.
What was missing was only a note-taking platform that would be able to house this work, allowing researchers simultaneous access to the collection. We then transfer the collection to a cloud infrastructure equipped with this capacity and start the classification. A simplified example of how data is structured, taking writs of mandamus as an example, is the following:
Although some parts of the table have been omitted (which preserves the originality of the research until its publication), it is already possible to notice the structure we set up for annotation of the mode (majority or unanimous). As an example, in the case of extraordinary appeals, we classified 3,972 judgments as unanimous, with the following variations: unanimous, unanimous, unanimous, agreement of votes and uniform decision.
This means that, at this point, Our database now has almost four thousand links properly labeled. They are real processes, of which we know several attributes. The same philosophy applies to the vocabulary present in the collection to classify the outcome (positive or negative) of the judgment. The difference is that there are not just five, but hundreds of variations of words used to translate the outcome of a judgment.
As we know a lot about each of these processes, it becomes possible to train a machine so that, recognizing a pattern, it suggests a label contemplating the mode (e.g., unanimous) and the outcome (e.g., unfavorable) in the face of a new judgment that may be handed down. Thus, we teach the machine to quickly classify thousands of new decisions, based on the curation carried out by our researchers.
Machine learning itself is also not a trivial task and will be the subject of a new post. So far, we have only dealt with data preparation , which is an essential and often overlooked step. Without properly organized data, it is not possible to develop artificial intelligence solutions.